

Prometheus / Grafana란?

프로메테우스(Prometheus)와 그라파나(Grafana)는 메트릭 수집 및 시각화에 사용되는 가장 인기 있는 모니터링 오픈소스 도구로 Grafana Labs라는 회사에서 개발했다.
프로메테우스는 서버, 애플리케이션 및 기타 시스템에서 발생하는 데이터를 모니터링하는 도구로, 시간에 따라 변하는 메트릭(ex: CPU 사용률, 메모리 사용량 등)을 수집하고 저장한다, 또한 사용자가 정의한 규칙에 따라 경고를 생성하여 시스템의 건강 상태를 모니터링하고 문제가 발생할 경우 알람이 가도록 하는 등 여러 가지 기능을 지원한다.
그라파나는 프로메테우스와 같은 모니터링 도구에서 수집된 메트릭 데이터를 시각적으로 표시하는 도구다. 사용자가 원하는 형태(그래프, 표, 퍼센티지 등)로 대시보드를 구성하여 복잡하고 읽기 어려운 메트릭 데이터를 쉽게 이해하고 분석할 수 있도록 돕는다. 이를 통해 사용자는 시스템의 상태 및 성능을 실시간으로 모니터링할 수 있다.
동일한 회사에서 개발하여 서로 호환성이 좋다는 장점도 있지만 무료 버전으로도 다양한 기능들을 제공하여 모니터링 도구로서 충분히 역할을 수행할 수 있기 때문에 많은 환경에서 같이 사용되고 있다.
Prometheus-Grafana 동작 구조
프로메테우스와 그라파나가 같이 사용될 때 어떻게 두 개의 시스템이 연동되는지에 대해 정리해 보았다.
어떤 환경에서 모니터링 도구를 사용하는지에 따라 조금씩 달라지긴 하겠지만 대부분 아래와 같이 동작한다.

먼저 Node-exporter가 클라이언트 역할로 실제 애플리케이션이 구동되고 있는 환경에 설치된 후 메트릭 정보들을 수집한다. 메트릭 데이터가 수집된 이후에는 해당 데이터를 Prometheus 서버에 전송하고 Prometheus 서버는 받은 데이터들을 자신의 데이터베이스에 저장하여 관리한다.
Grafana는 대시보드에서 요구하는 메트릭 데이터를 Prometheus서버에 요청하는데 요청과정에서 PromQL이라는 프로메테우스의 전용 쿼리문을 이용하여 프로메테우스 서버에 질의한다. 해당 질의 요청을 받은 Prometheus 서버는 내용을 확인 후 해당하는 메트릭 데이터 정보를 Grafana에 응답해 준다.
이러한 과정을 거쳐 사용자에게 메트릭 데이터가 대시보드 형태로 출력되게 된다.
Prometheus-Grafana 설치
간단하게 Prometheus와 Grafana를 설치하여 쿠버네티스의 클러스터 상태를 모니터링하는 실습을 진행해 본다.
설치 방법은 여러 가지가 있지만 Prometheus-Stack이라는 Helm차트를 이용해 설치해 본다.
Prometheus-stack은 Prometheus, Grafana, Alertmanager 등 다양한 구성 기능들을 한 번에 관리하고 설치할 수 있도록 Grafana labs에서 관리해 주는 Helm 차트이다.
- Helm repo 추가
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts- Helm chart 다운
차트 버전은 2024년 4월 6일에 업데이트된 57.2.1 버전을 사용한다.
$ helm pull prometheus-community/kube-prometheus-stack --version 57.2.1- values.yaml 작성
alertmanager:
enabled: true
ingress:
enabled: true
ingressClassName: nginx
hosts:
- alertmanager.hokka.com
paths:
- /
pathType: ImplementationSpecific
grafana:
enabled: true
ingress:
enabled: true
ingressClassName: nginx
hosts:
- grafana.hokka.com
paths:
- /
pathType: ImplementationSpecific
persistence:
enabled: true
type: sts
storageClassName: "nfs-client"
accessModes:
- ReadWriteOnce
size: 20Gi
nodeExporter:
enabled: true
prometheus:
enabled: true
ingress:
enabled: true
ingressClassName: nginx
hosts:
- prometheus.hokka.com
paths:
- /
pathType: ImplementationSpecific
prometheusSpec:
retention: 10d
retentionSize: ""alertmanager, nodeExporter, prometheus, grafana를 설치하기 위해 enabled를 true로 변경해 준다.
또한 그라파나의 경우 대시보드, 계정정보 등 데이터가 유지돼야 하는 기능들이 있기 때문에 외부볼륨인 nfs와 연결하여 볼륨을 연결해 준다.
서비스 노출 방법으로는 nodeport를 사용해도 되나 서비스 간 구분을 위해 ingress로 별도 주소를 부여해 준다.
가장 밑에 prometheusSpec에 있는 retention/retentionSize는 수집한 메트릭 데이터를 어느 조건동안 가지고 있을지 설정하는 부분으로, retention을 사용할 시 일수로 구분하고 retentionSize를 사용할 시 수집된 메트릭 데이터의 용량으로 보유조건을 설정할 수 있다.
- Helm install
$ helm install -n monitoring kube-prometheus-stack kube-prometheus-stack -f values.yaml --create-namespace잘 설치되었는지 Pod와 기타 리소스들을 출력해 본다.
$ kubectl get all -n monitoring
NAME READY STATUS RESTARTS AGE
pod/alertmanager-kube-prometheus-stack-alertmanager-0 2/2 Running 2 (55m ago) 5h54m
pod/kube-prometheus-stack-grafana-0 3/3 Running 2 (55m ago) 5h54m
pod/kube-prometheus-stack-kube-state-metrics-74c4656fd6-zhpms 1/1 Running 2 (44m ago) 5h54m
pod/kube-prometheus-stack-operator-746cdd7d8b-f67lk 1/1 Running 1 (55m ago) 5h54m
pod/kube-prometheus-stack-prometheus-node-exporter-gtsmb 1/1 Running 1 (55m ago) 5h54m
pod/kube-prometheus-stack-prometheus-node-exporter-m84d9 1/1 Running 1 (55m ago) 5h54m
pod/kube-prometheus-stack-prometheus-node-exporter-zdjlq 1/1 Running 1 (55m ago) 5h54m
pod/prometheus-kube-prometheus-stack-prometheus-0 2/2 Running 0 9m45s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 5h54m
service/kube-prometheus-stack-alertmanager ClusterIP 10.103.0.151 <none> 9093/TCP,8080/TCP 5h54m
service/kube-prometheus-stack-grafana ClusterIP 10.107.216.254 <none> 80/TCP 5h54m
service/kube-prometheus-stack-grafana-headless ClusterIP None <none> 9094/TCP 5h54m
service/kube-prometheus-stack-kube-state-metrics ClusterIP 10.96.209.132 <none> 8080/TCP 5h54m
service/kube-prometheus-stack-operator ClusterIP 10.105.93.140 <none> 443/TCP 5h54m
service/kube-prometheus-stack-prometheus ClusterIP 10.103.208.148 <none> 9090/TCP,8080/TCP 5h54m
service/kube-prometheus-stack-prometheus-node-exporter ClusterIP 10.110.171.215 <none> 9100/TCP 5h54m
service/prometheus-operated ClusterIP None <none> 9090/TCP 5h54m
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/kube-prometheus-stack-prometheus-node-exporter 3 3 3 3 3 kubernetes.io/os=linux 5h54m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/kube-prometheus-stack-kube-state-metrics 1/1 1 1 5h54m
deployment.apps/kube-prometheus-stack-operator 1/1 1 1 5h54m
NAME DESIRED CURRENT READY AGE
replicaset.apps/kube-prometheus-stack-kube-state-metrics-74c4656fd6 1 1 1 5h54m
replicaset.apps/kube-prometheus-stack-operator-746cdd7d8b 1 1 1 5h54m
NAME READY AGE
statefulset.apps/alertmanager-kube-prometheus-stack-alertmanager 1/1 5h54m
statefulset.apps/kube-prometheus-stack-grafana 1/1 5h54m
statefulset.apps/prometheus-kube-prometheus-stack-prometheus 1/1 5h54mvalues 파일에서 활성화 한 서비스 4개(nodeExporter, Prometheus, Grafana, Alertmanager)와 ingress가 정상적으로 생성된 걸 확인할 수 있다.
Prometheus 다뤄보기
설치가 완료된 프로메테우스에 접속하여 간단한 PromQL 쿼리문을 입력하여 결과를 확인해 본다.
- ingress를 통해 프로메테우스 접속
Graph는 메인페이지로 프로메테우스 서버에 쿼리로 데이터를 요청하여 결과를 받아 볼 수 있다.

Alerts는 기본적으로 클러스터 운영에 필요한 기본 룰들이 만들어져 있는 것을 볼 수 있다.

Status는 프로메테우스 서버(DB, Target, Configuration 등)와 rule들에 대해 현재 상태를 확인할 수 있다.
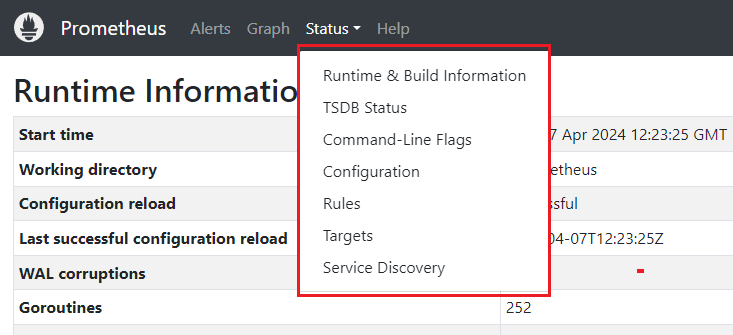
- PromQL문을 통해 데이터 요청하기
현재 클러스터에 배포된 Pod의 개수를 출력하는 PromQL문을 요청해 본다.

응답을 확인해 보면 39라는 응답이 온 것을 볼 수 있다.
그럼 실제로 39개의 Pod가 배포되고 있는지 확인해 보자.
$ kubectl get pod -A | tail -n +2 | wc -l
실제 kubectl 명령으로 확인해 본 결과 배포된 Pod의 개수가 39개로 일치하는 것을 확인할 수 있다.
이외에도 클러스터 노드의 사용가능한 메모리양을 출력하는 PromQL 등 여러 가지 메트릭 데이터들을 요청할 수 있다.

Grafana 다뤄보기
배포된 Grafana 페이지에 접속하여 로그인을 해본다.
- ingress를 통해 그라파나 접속
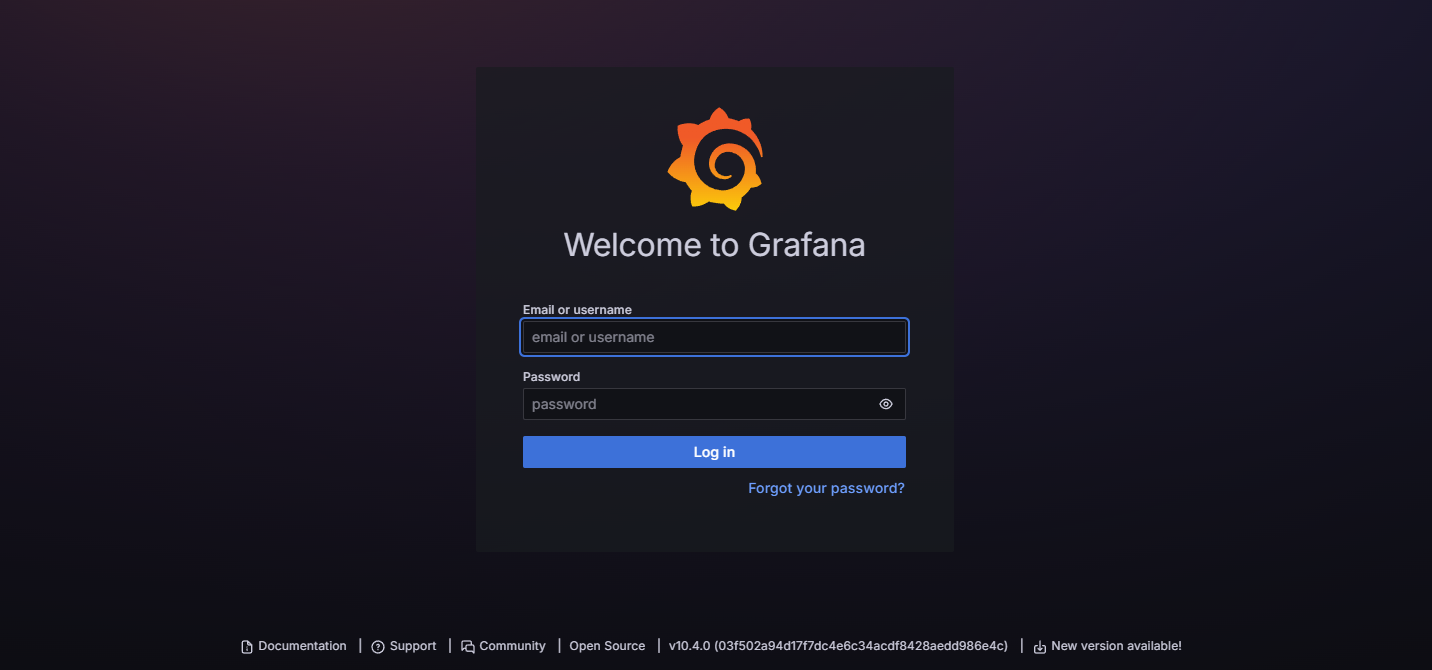
로그인 창이 뜨는 것을 볼 수 있는데 별도의 설정을 하지 않았다면 prometheus-stack으로 그라파나를 설치했을 경우 기본 계정정보는 admin/prom-operator이다.

로그인을 완료하면 그라파나에 정상적으로 접속되는 것을 볼 수 있다.
접속 후에 왼쪽 사이드바에 있는 메뉴들을 확인해 보면 아래와 같다.

Dashboards에서는 대시보드를 직접 만들거나 타인이 만들어놓은 대시보드를 불러올 수 있다.
Explore에서는 추가한 Data Source에 대해 그라파나에서 데이터를 요청하여 결과를 출력할 수 있다.
Alerting은 특정 조건을 추가하여 경보를 생성하고, 해당 경보가 활성화되면 알람이 가도록 설정할 수 있다.
Connections은 여러 가지 애플리케이션을 Grafana의 데이터 소스로 사용할 수 있도록 추가할 수 있다.
Administration은 그라파나와 관련하여 계정 관리, 플러그인 관리 등을 수행할 수 있다.
- Prometheus와 연동하기
그라파나와 프로메테우스를 연동하기 위해서는 Connections 탭에서 프로메테우스 서버를 Data source로 추가해야 한다.
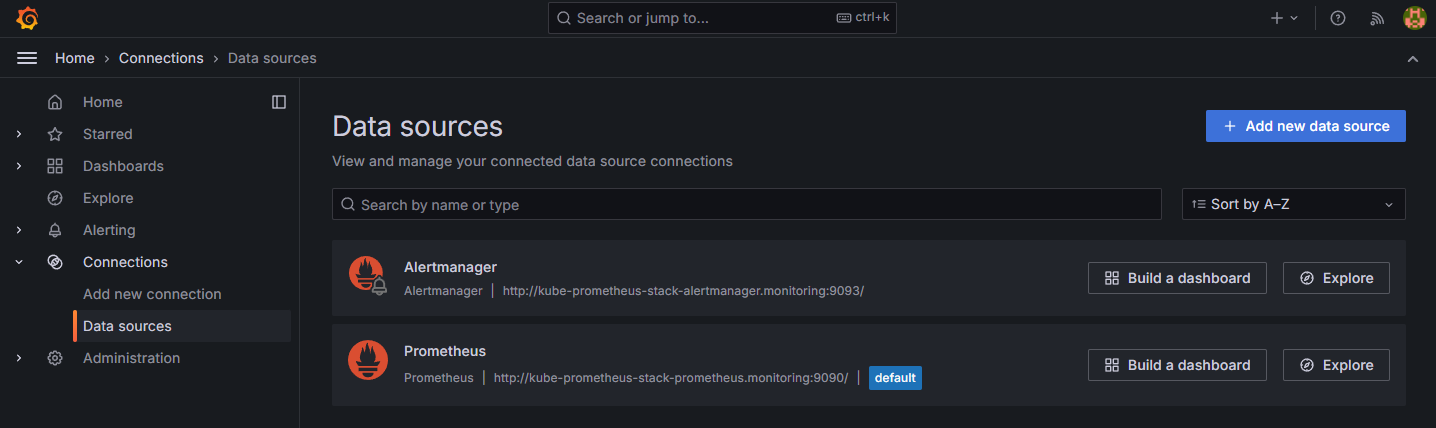
Data source 페이지를 가보면 helm으로 설치한 alertmanager와 prometheus가 자동으로 추가되어 있는 것을 볼 수 있다.
이는 prometheus-stack으로 같이 설치를 진행했기 때문에 자동으로 추가 구성이 되어있는 것이다.
만약 외부 프로메테우스 서버나 다른 애플리케이션을 추가하고 싶다면 우측 상단에 Add 버튼을 통해 구성해 주면 된다.

실제로 확인해 보면 프로메테우스를 제외하고도 같은 시계열 DB인 InfluxDB, 로깅 시스템에서 자주 사용되는 ElasticSearch 등 다양한 상용 도구들과 연결할 수 있는 플러그인들을 지원하는 것을 볼 수 있다.
추가로 자동 설정되어 있는 프로메테우스 정보를 확인해 보면 URL 부분이 [IP:Port]가 아닌 [Domain:Port] 형식으로 지정되어 있는 것을 볼 수 있다.

이는 Prometheus와 Grafana가 같은 클러스터에 배포되어 있는 상태이기 때문에 CoreDNS 내부주소로 서로를 호출할 수 있어서 가능한 설정이다.
- Grafana 대시보드 구성하기
대시보드는 사용자가 직접 만들 수도 있지만 상용 대시보드의 경우 여러 커뮤니티에서 정말 좋은 것들이 많이 제공되고 있기 때문에 다운로드하여 import 시켜서 쓰는 것이 좋다.
대시보드 커뮤니티는 여러 개가 있지만 Grafana labs에서 운영하는 공식 커뮤니티를 사용해 본다.
Dashboards | Grafana Labs
Thank you! Your message has been received!
grafana.com
어떤 대시보드를 사용해 볼까 고민하다가 클러스터 노드들의 정보를 확인할 수 있는 대시보드를 추가해 보기로 했다.
Kubernetes / Views / Nodes | Grafana Labs
Thank you! Your message has been received!
grafana.com

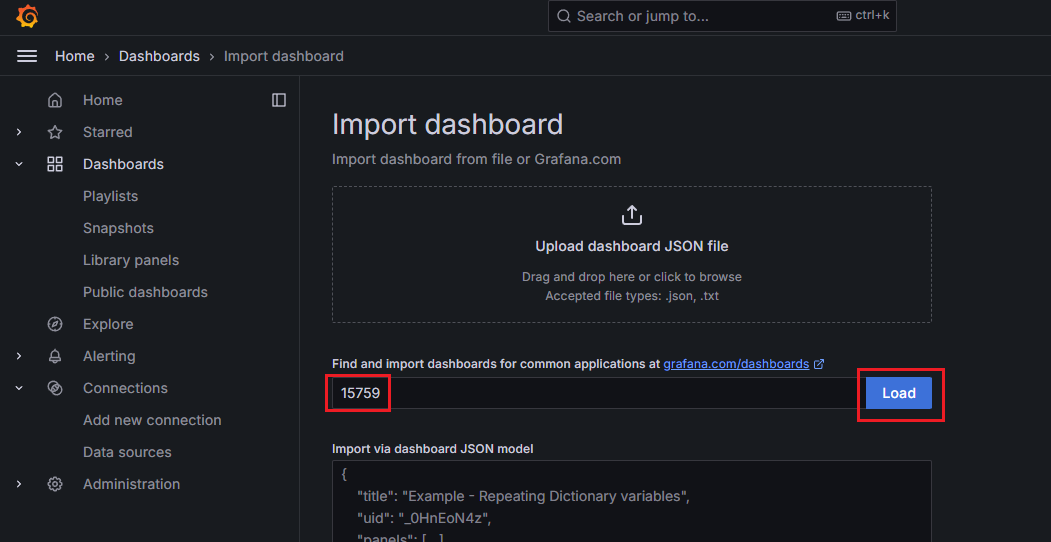
대시보드를 추가하는 방법에는 JSON 파일로 추가하는 법과 대시보드의 ID로 추가하는 법이 있는데 해당 글에서는 ID로 간단하게 추가해 보았다.
대시보드의 ID를 확인하는 방법은 대시보드 상세 페이지에서 Copy ID to clipboard 버튼을 클릭하면 된다.
이후 그라파나 페이지로 돌아와서 Dashboards > New > Import 버튼을 클릭한다.

그리고 복사해 둔 대시보드의 ID를 붙여 넣고 Load 버튼을 누르면 된다.
추가 과정에서 데이터 소스를 선택해야 하는데 여기서는 클러스터의 메트릭을 모니터링하기 위함이므로 helm으로 같이 설치했던 프로메테우스를 지정해 준다.
모두 완료되면 아래와 같이 커뮤니티에서 봤던 대시보드가 그라파나에 추가된 것을 볼 수 있다.
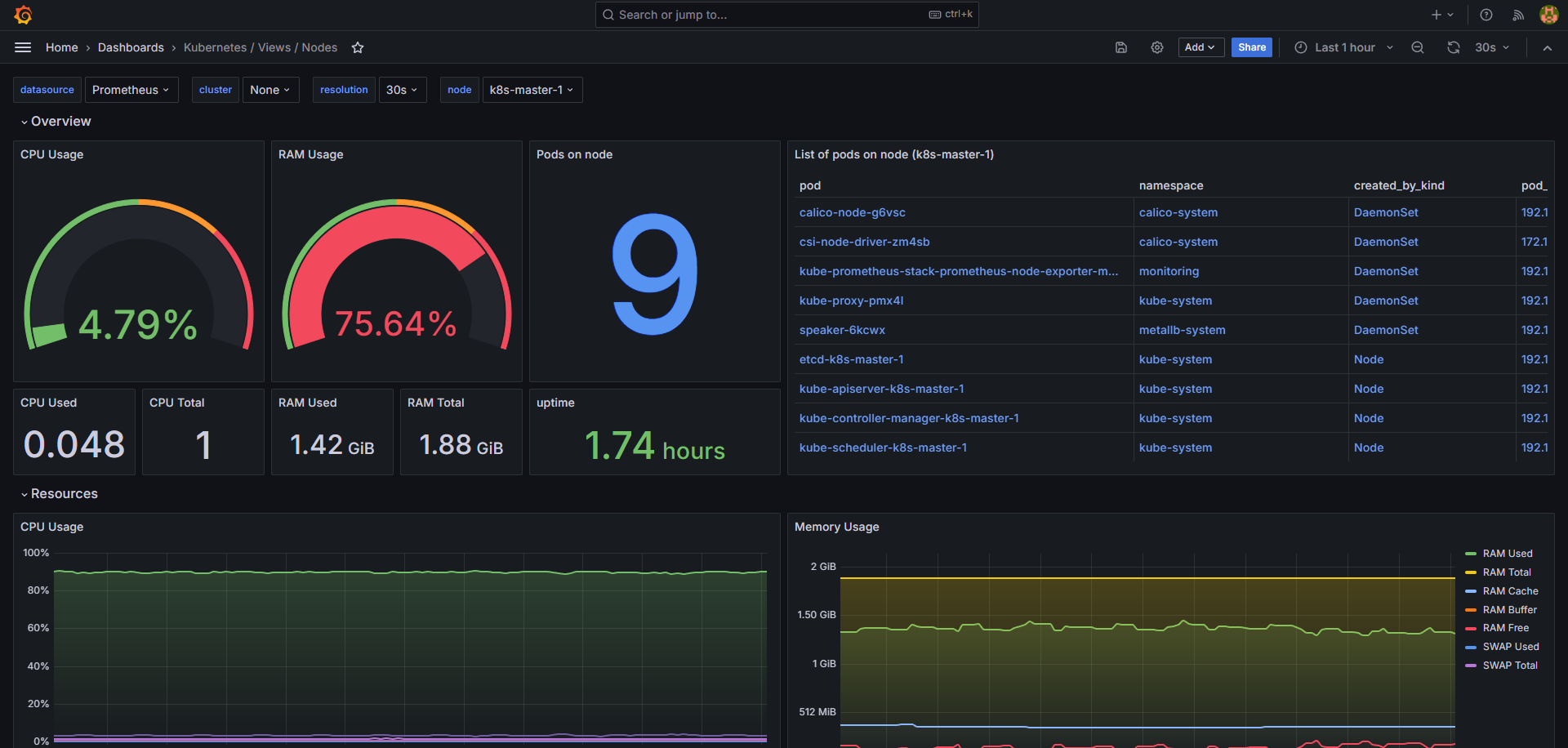
만약 데이터값이 제대로 출력되지 않거나 No data로 출력된다면 아래 그림처럼 Edit 기능을 통해 쿼리문을 점검해 보면 된다.

참고자료
helm-charts/charts/kube-prometheus-stack at main · prometheus-community/helm-charts
Prometheus community Helm charts. Contribute to prometheus-community/helm-charts development by creating an account on GitHub.
github.com